 毎日の作業に疲れた人
毎日の作業に疲れた人仕事をしているとWebサイトからデータを取得し、EXCELにコピペして情報をまとめたり分析する機会があります。
これ、自動化できたら楽なのに…て思うときありませんか?
ウェブスクレイピングを使えばWebサイトからデータを自動取得できるようになります。
しかも、Googleスプレッドシートでできるので、無料でできます。
- WEBサイトからのコピペがだるい
- 日々のルーティン作業を効率化したい
- 知識0からできるこをしたい
今日はウェブスクレイピングでできることと、一番簡単で初歩のスクレイピング方法を解説します。
 旅行業でマーケティングを担当
旅行業でマーケティングを担当人手不足の中小企業で業務の効率化をしている
お金をかけずに業務効率化をするのが得意
Webサイトからデータ抽出!importxml関数で初めてのウェブスクレイピング
スクレイピングの基礎知識
ウェブスクレイピングとはWebサイトから情報を抽出する作業です。
任意の情報や、数字、画像などの情報を抽出することができます。
主に3つの方法があります
- Googleスプレッドシート
- Google Apps Script
- Python
下にいくにつれて難易度があがります。
今日はこの中でも一番簡単なGoogleスプレッドシートで、一番最初にできるスクレイピングの方法を紹介します。
Googleスプレッドシートとは?
GoogleスプレットシートとはGoogleが提供している無料の表計算ソフトです。
ブラウザ上で使えるので、ソフトやアプリをインストールする必要もありません。
MicrosoftのEXCELと似たもので、EXCELが使える人なら違和感なく使うことができます。
EXCELとのメリットとデメリットを比較してみました。
まずはメリットから。
- 無料で使える
- Googleの他のサービスと連携ができる
- 共有が簡単
まず最大のメリットは有料のEXCELに対して無料だということです。
またGoogleドキュメントやGoogleフォームなどGoogleの他のサービスとも連携が可能です。
Googleアカウントを持っている相手であれば簡単に閲覧と編集の共有が簡単にできるのも特徴です。
次にデメリットです。
- Wi-Fi環境がないと使えない
- EXCELと比較すると動きが鈍い
- Googleアカウントが必要
WebアプリケーションなのでWi-Fi環境がない場所では使用できません。
またEXCELと比べるとどうしても操作性能が落ちてしまいます(慣れればコツを掴めますが)。
Googleアカウントが必要ですが、Gmailと同じものなので新しく作る必要はありません。
こんな感じですが、もしまだスプレッドシートを利用したことがない方は、ぜひ一度触れてみてください。
https://www.google.com/intl/ja_jp/sheets/about/
ここまで読んだ方は気がついたかと思いますが、スプレットシートはWebアプリケーションのため、Web上のデータを取得するウェブスクレイピングに向いているのです。
初めてのスクレイピングimportxml関数
ということで、さっそくスクレイピングをしてみたいと思います。
- 新規のスプレッドシートを作成する
- importxmlの解説
- xpathを取得する
- 引数をimport関数にいれる
- スプレッドシードに入力する
本当に簡単なので、ぜひこれを読みながら一度試してみてください。
①新規のスプレッドシートを作成する。
まずはGoogleアカウントにログインして、下記から新規のスプレッドシートを作成してください。
https://www.google.com/intl/ja_jp/sheets/about/
②importxmlの解説
さて、次にimportxmlの関数の説明です。
=importxml("url","xpathクエリ")上記がWebサイトからデータ取得をするための最もシンプルな関数の形になります。
要素を一つずつ分解して紹介していきます。
<importxml>
これはWebサイトから構造化されたデータを読み込む(インポートする)ということを命令する関数です。
Googleからの公式説明は下記から。
https://support.google.com/docs/answer/3093342?hl=ja
今はまだ分からなくても、とりあえずこういう関数があるというだけで次に進んでください。
<url>
第一引数には取得したいWebサイトのurlを入力します。
今日は試しにこのブログのurlとしてみます。
urlは””で囲みます。
"https://nezumibooks.jp/"<xpathクエリ>
第二引数には取得したい箇所のxpathを入力します。
xpathとはxmlの構造を記述したものです。
Webサイトを記述するためのhtmlやxmlなどの言語をマークアップ言語といいます。
htmlが対人間が読み取りやすいマークアップ言語だとすれば、xmlはコンピューターが読み取りやすいマークアップ言語です。
スプレッドシートではxpathをつかってマークアップ言語内のxmlを読み取らせます。
これも今の段階では深く理解しなくても次に進められます。
③xpathを取得する
さて、ではそのxpathですが、とても簡単に取得することができます。
ここでは当ブログのトップページから最新記事のタイトルを取得してみます。
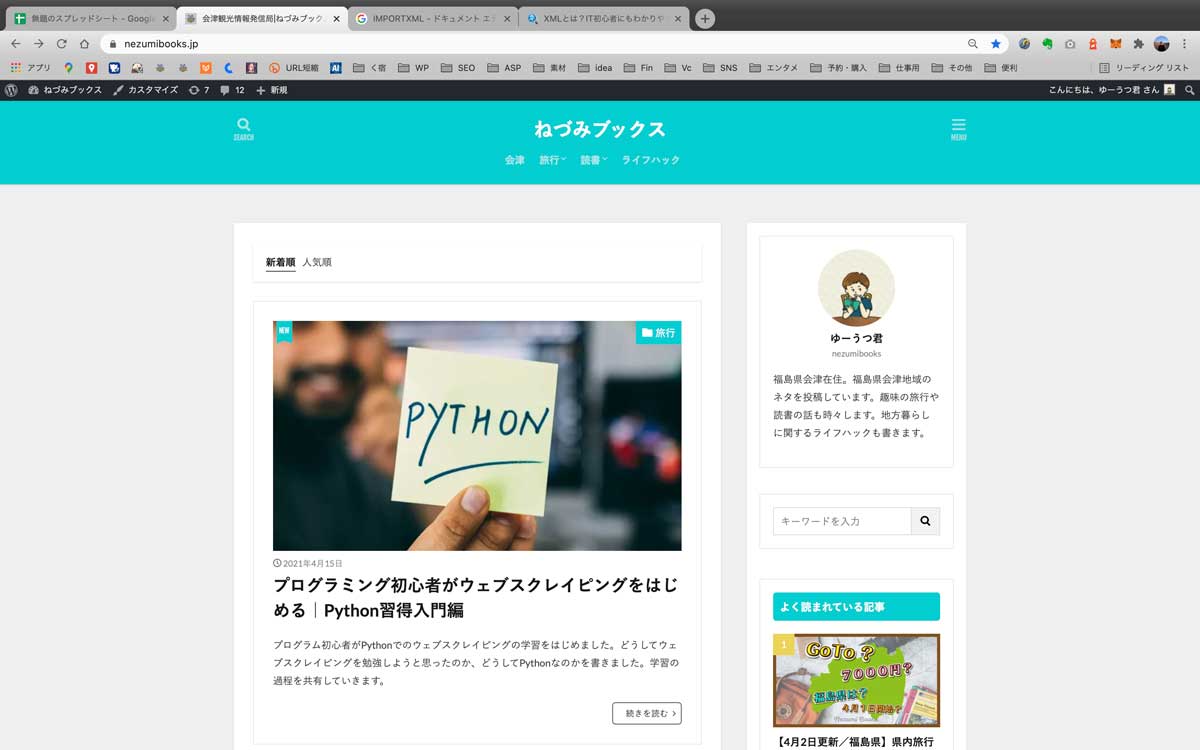
- 取得したいデータをドラッグする
- 右クリックで「検証」を押す
- ドラッグした箇所のHTMLが自動で選択される
- 選択箇所で右クリック「Copy」→「Copy Xpath」を押す
1.取得したいデータをドラッグする
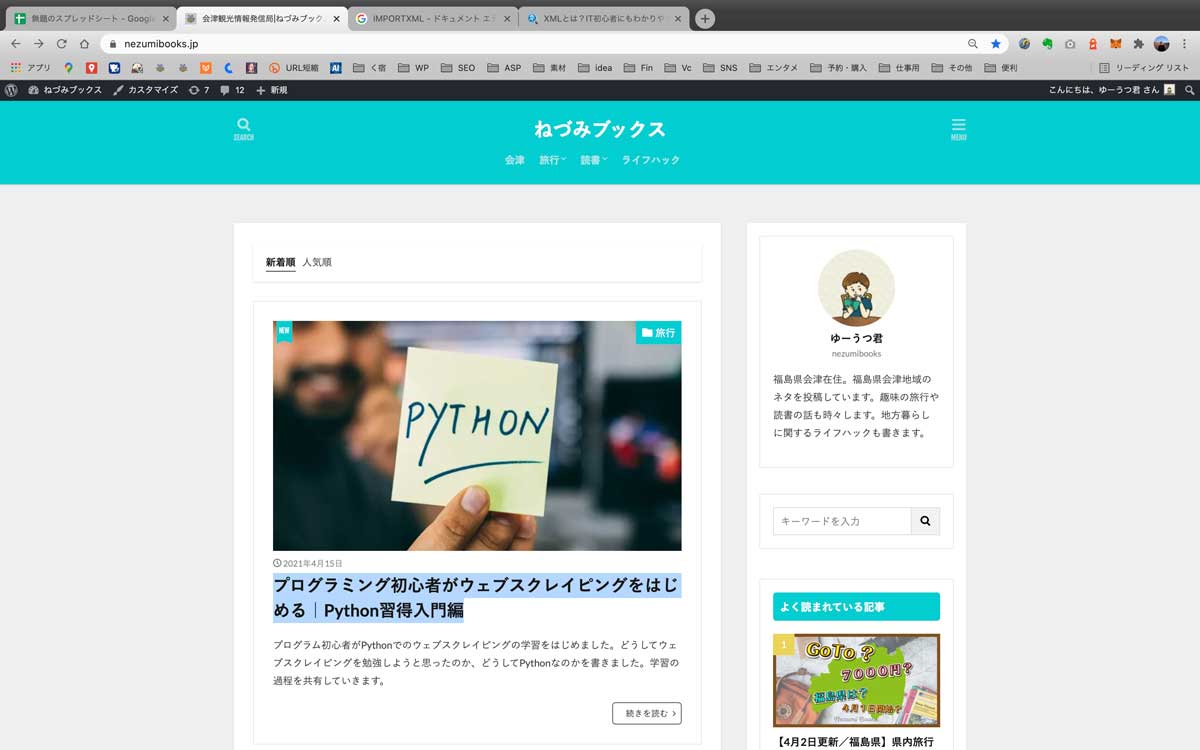
2.右クリックで「検証」を押す
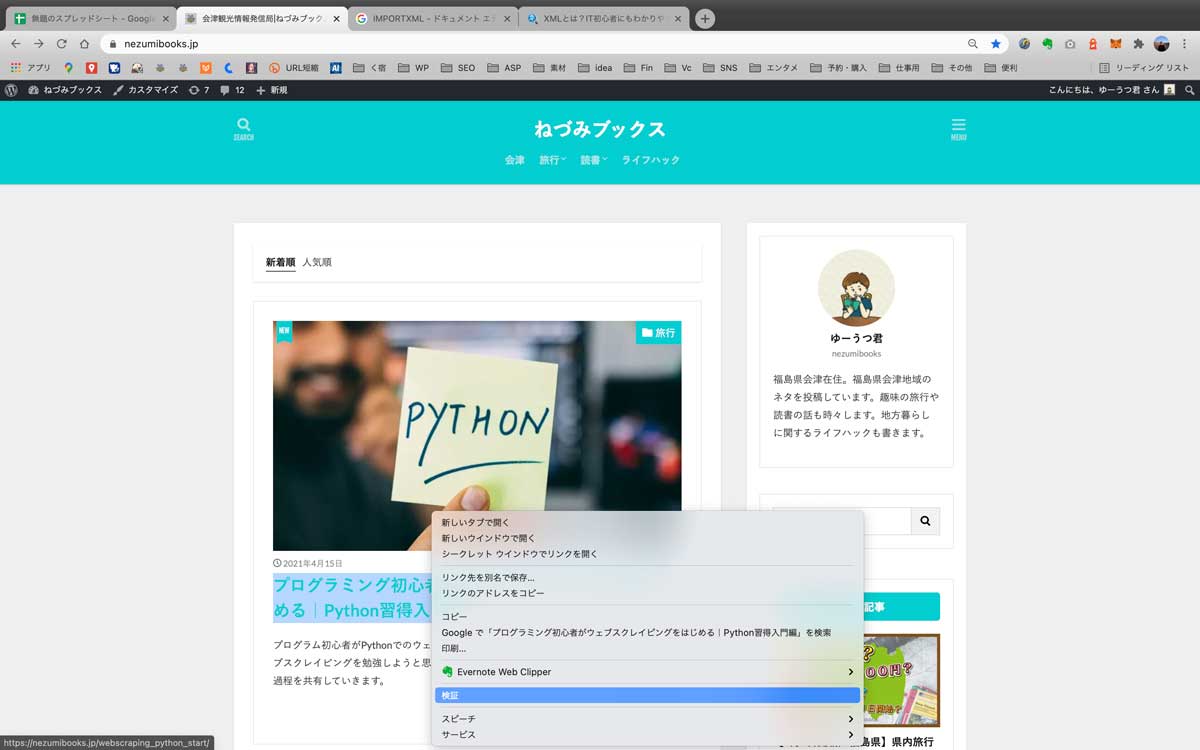
3.ドラッグした箇所のHTMLが自動で選択される
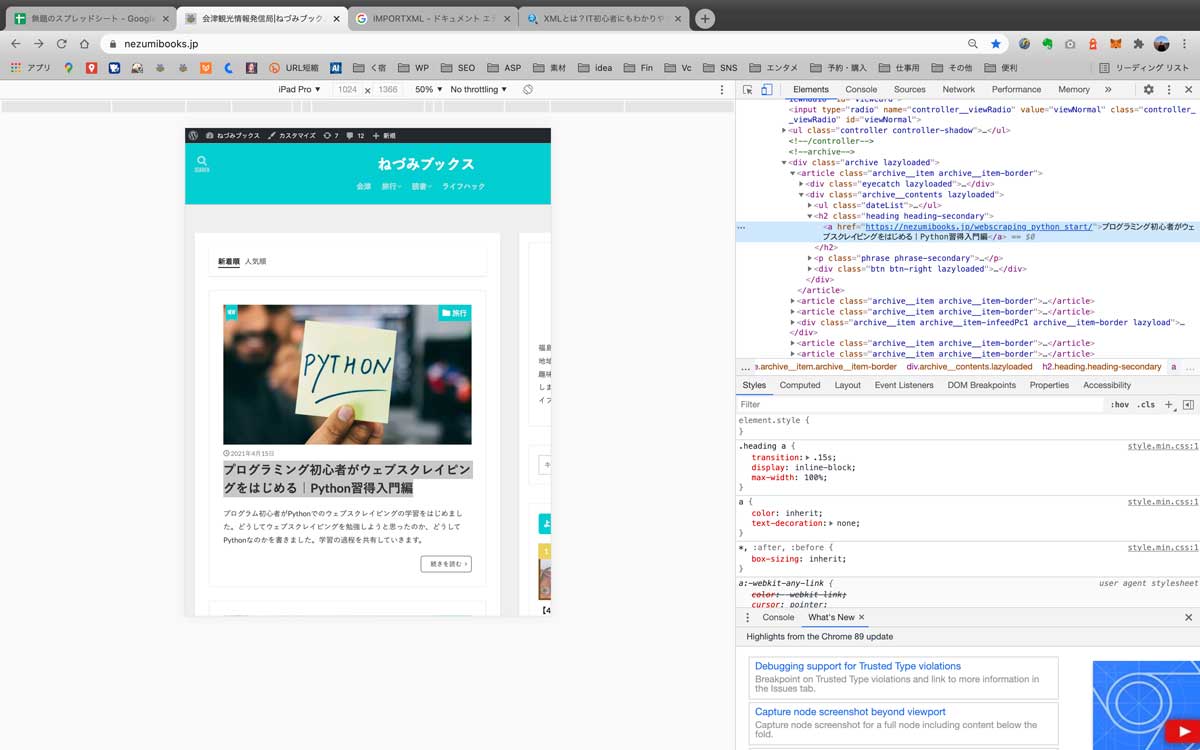
4.選択箇所で右クリック「Copy」→「Copy Xpath」を押す
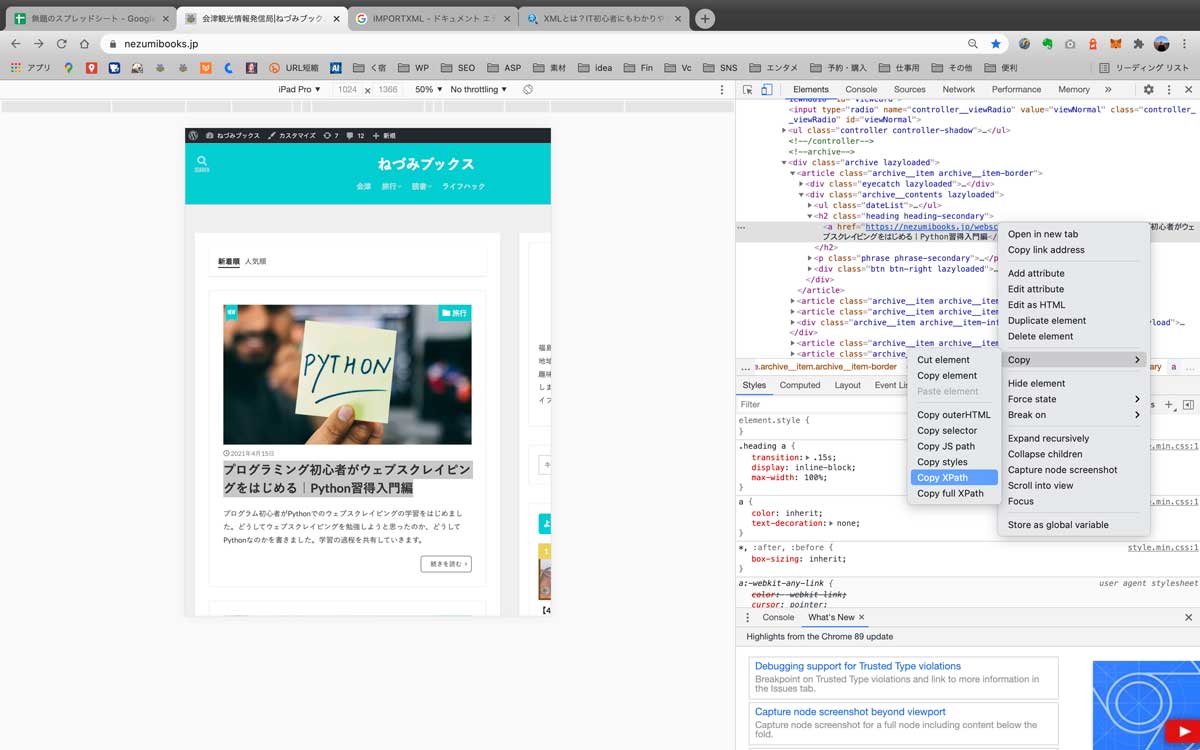
これでXpathが取得できました。
取得できたXpathは下記ですね。
//*[@id="top"]/div[3]/main/div/div/article[1]/div[2]/h2/aこれも””で囲みます。
(macは「shift」+「2」で”)
"//*[@id="top"]/div[3]/main/div/div/article[1]/div[2]/h2/a"HTMLを勉強すると、これがどのような構造を示しているかが分かるようになります。
今はこうすることでXpathを取得することが分かればOKです。
④引数をimport関数にいれる
さて、ここまで取得できたURLとXpathのデータをimportxml関数にいれてみましょう。
=importxml("https://nezumibooks.jp/","//*[@id="top"]/div[3]/main/div/div/article[1]/div[2]/h2/a")ただ、これだとエラーになってしまい一部を訂正する必要があります。
Xpathの”top”の部分、Xpathを囲む””が二重にかかっている状態になっているため、topの部分を”に変えます。
(macなら「shift」+「7」)
するとこうなります。
=importxml("https://nezumibooks.jp/","//*[@id='top']/div[3]/main/div/div/article[1]/div[2]/h2/a")⑤スプレッドシードに入力する
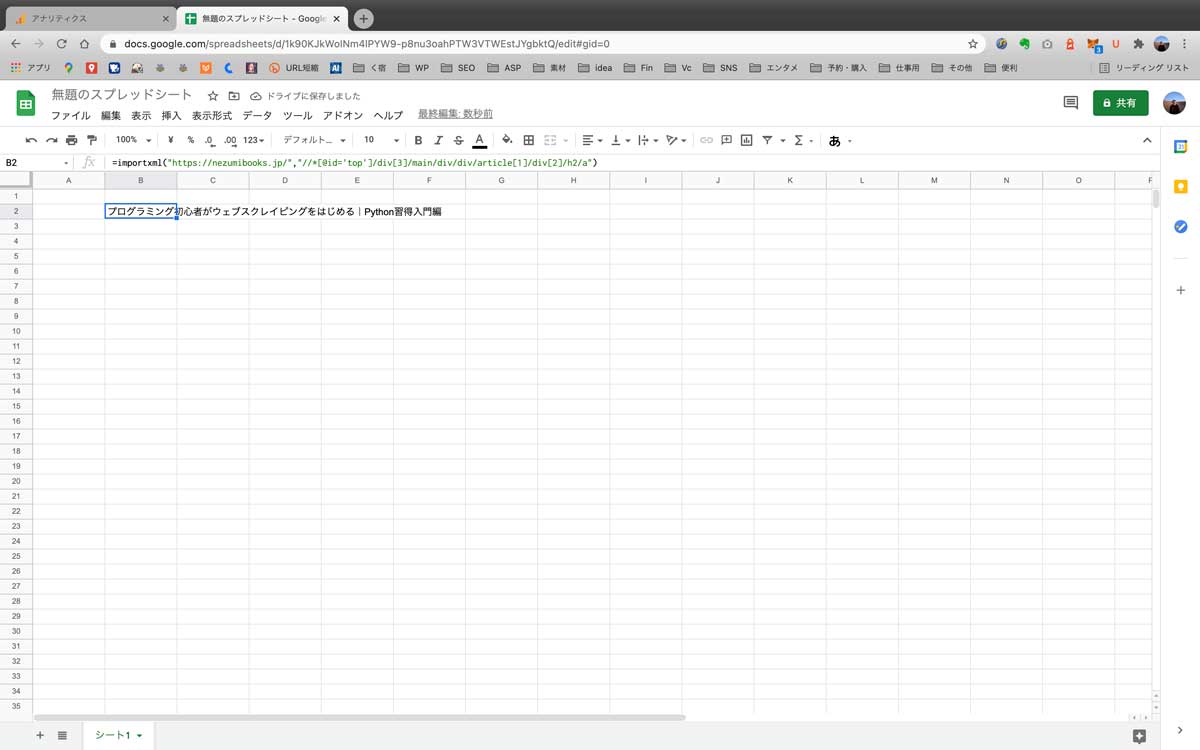
=importxml("https://nezumibooks.jp/","//*[@id='top']/div[3]/main/div/div/article[1]/div[2]/h2/a")こちらをスプレッドシートにコピペしてみてください。
すると当ブログの最新記事のタイトルが反映されます。
スクレイピングの勉強におすすめ
以上がimportxml関数でのスクレイピングになります。
どうでしょう?思ったよりは簡単ではないでしょうか。
もっともシンプルなスクレイピングで、これができたからといって、すぐに業務の自動化や効率化にいかせるわけではありませんが、まずは基礎ということでここからスタートしましょう。
今回の記事でスクレイピングに興味をもち、もう少し深く勉強したい方は、まだHTMLの基礎を学ぶのがおすすめです。
「HTML」と検索するとWeb記事でもYoutubeでも参考になる記事がたくさんありますので、ぜひ参照してみてください。
参考書を一冊、家に置いておくのもいいかもしれません。

ねづ店長のワンポイントアドバイス

スクレイピングは奥が深いよ。新しいことに挑戦してみてね。